
Quando imaginamos ver robôs chorando e interagindo como humanos, vislumbramos cenas de filmes renomados de ficção futurista. Mas para pesquisadores do Instituto Avançado de Ciência e Tecnologia do Japão, e da Universidade de Tianjin e do Laboratório Pengcheng, ambos da China, isso já pode ser uma realidade, brevemente.
Hoje, apesar dos robôs e agentes virtuais já serem perfeitamente capazes de se comunicar com humanos através da fala, e processarem instruções lógicas; ainda não conseguem registrar emoções como felicidade, tristeza e raiva, tão compreendidas pelos humanos.
Pensando, então, em humanizar cada vez mais os robôs, áreas como neurociência cognitiva, robótica e mecatrônica têm realizado pesquisas sobre HRI (Human-Robot Interaction- interação humano-robô) a respeito do reconhecimento de emoções a partir da fala.Os pesquisadores têm se baseado nas “emoções dimensionais”, que constituem uma transição emocional gradual na fala natural, onde um modelo de percepção auditiva simula o funcionamento de um ouvido humano que pode gerar “pistas de modulação temporal”, que capturam fielmente a dinâmica temporal das emoções dimensionais.
Para o prof. Masashi Unoki do Instituto Avançado de Ciência e Tecnologia do Japão (JAIST), que trabalha com sistemas de reconhecimento e processamento de voz na robótica, “… a emoção dimensional contínua pode ajudar um robô a capturar a dinâmica do tempo, do estado emocional de um locutor e, consequentemente, ajustar sua forma de interação e conteúdo em tempo real”.
Etapas da pesquisa
Na pesquisa ”Recurso de Cócleagrama filtrado por Modulação de Resolução Múltipla para Reconhecimento de Emoção Dimensional baseado em LSTM”, publicada na Neural Networks ; pesquisadores da Universidade de Tianjin (que liderou o estudo) e do Laboratório Pengcheng, ambos da China, e do JAIST, se inspiraram em uma descoberta recente em neurociência cognitiva, sugerindo que nosso cérebro forma múltiplas representações de sons naturais com diferentes graus de espectral (frequência) e resoluções temporais por meio de uma análise combinada de modulações espectral-temporais.
A partir daí, eles propuseram um novo recurso chamado cócleagrama filtrado por modulação de resolução múltipla (MMCG), que combina quatro cócleagramas filtrados por modulação (representações de frequência de tempo do som de entrada) em diferentes resoluções para obter as pistas de modulação temporal e contextual.
Para a diversidade dos cócleagramas, os pesquisadores projetaram uma arquitetura de rede neural paralela chamada “memória longa de curto prazo” (LSTM), que modelou as variações de tempo de sinais de multirresolução dos cócleagramas e realizou experiências extensivas em dois conjuntos de dados de fala espontânea.
Depois disso, descobriram que o MMCG mostrou um desempenho de reconhecimento de emoção significativamente melhor do que os recursos tradicionais de base acústica e outros recursos de base auditiva, para ambos os conjuntos de dados. Além da rede paralela LSTM ter demonstrado uma previsão superior de emoções dimensionais do que com uma abordagem baseada em LSTM simples.
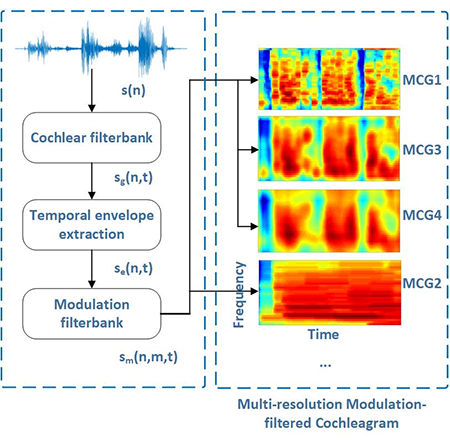
Figura 1: Extração de recursos de cócleagrama filtrado por modulação de resolução múltipla (MMCG)- O painel esquerdo mostra o processo de extração de pistas de modulação temporal do front-end auditivo, enquanto o painel direito mostra o cócleagrama filtrado por modulação (MCG1-MCG4) em quatro resoluções diferentes
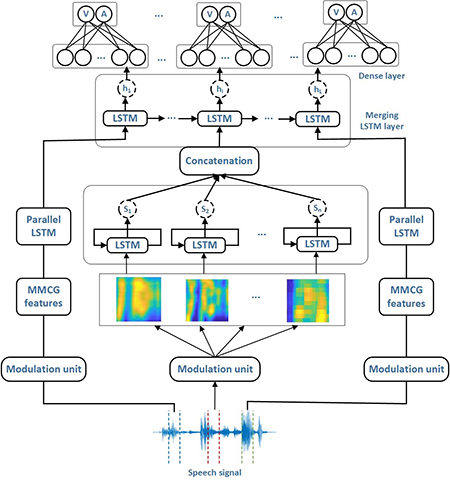
Figura 2: Arquitetura de rede LSTM paralela para reconhecimento dimensional de emoções. Uma rede LSTM paralela obtém recursos MMCG com diferentes resoluções e produz saídas que são concatenadas e enviadas para uma camada LSTM mesclada, e uma camada densa para produzir as sequências de valência (V) e excitação (A).
A próxima fase da pesquisa visa aprimorar o recurso MMCG, ao analisar as fontes de ruído ambiental e investigar seu recurso para outras tarefas, como reconhecimento de emoções categóricas, separação de fala e detecção de atividade de voz.
(Fontes e imagens: Instituto Avançado de Ciência e Tecnologia do Japão, e Sciencedirect.com /Edição: Samara Roriz)



